DBA MS SQL Server
Ola Hallengren: Statistics Optimize – jak ?
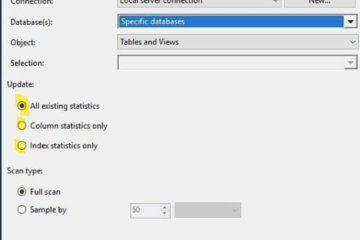
Statistics Optimize – czy to nowa procedura wspaniałego pakietu Ola Hallengrena ? Nie, poniżej przedstawię jak można za pomocą procedury IndexOptimize można było wykonać aktualizację samych statystyk bez przebudowy indeksów. Tematem tym zajmował się Brent Ozar i po napisaniu emaila do Ola Hallengrena otrzymał taką odpowiedź: Cała sztuczka polega na zadeklarowaniu następujących zmiennych jako NULL: